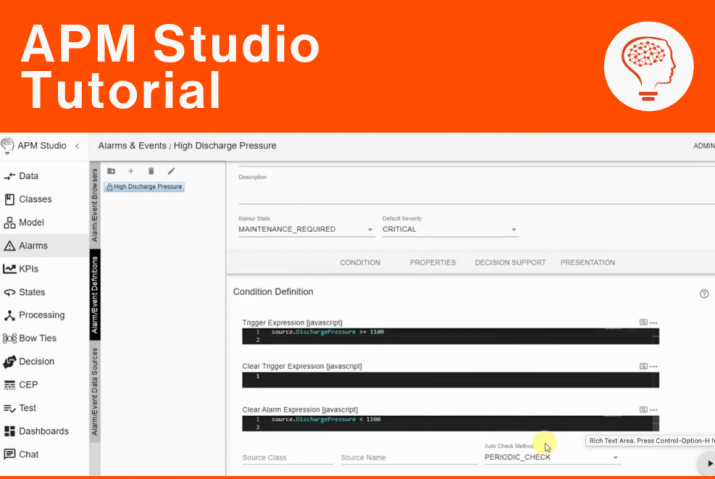
Systems that were meant to keep the process in control and inform operators of deviations, at BP Refinery in Texas City and Texaco Refinery in Milford Haven, were incapable of their basic task. As a result the operators in one case were given faulty alarm information whereas in the other case operators were flooded with too much alarm information not allowing timely response. It was very difficult for the operators to be aware of the situation that was developing.
Situational Awareness?
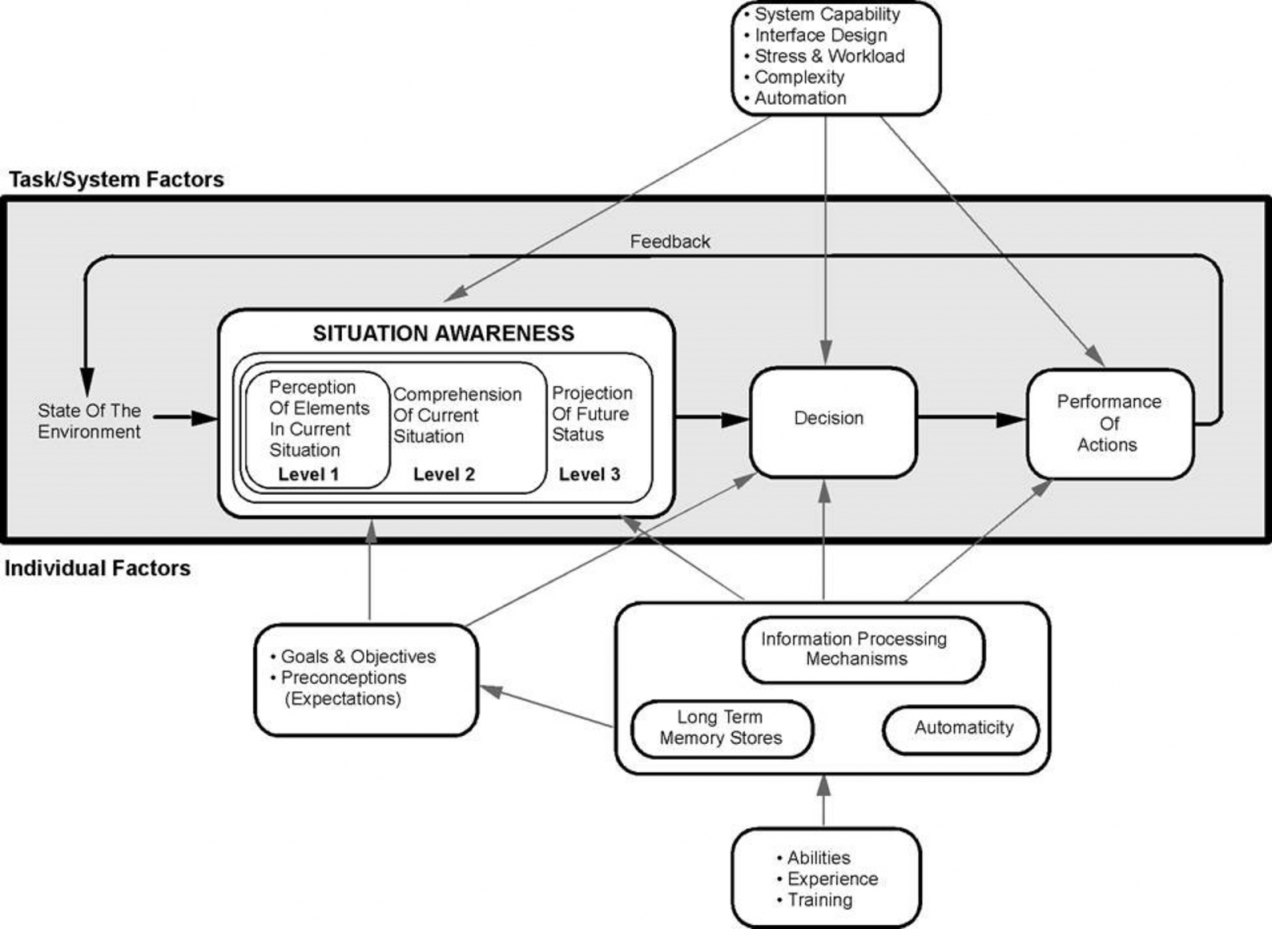
Situational Awareness means being aware of what is happening around you and understanding how information, events, and your actions will impact goals and objectives, both immediately and in the near future.
This is a broad definition that can be broken down into perceiving (gathering data), understanding it (creating a mental model) and thinking ahead – the situation triggers decision making and action that updates/changes the mental model. That is perfectly captured in Endsley’s theoretical model of Situational Awareness:
Not Just in Manufacturing
Situations where low situational awareness affects good decision making do not only exist in manufacturing industries. They exist in many other industries, below two examples:
1. Telecom, from 3GPP Study on Alarm Management:
The massive amount of network elements in a mobile system and the variety of network elements and infrastructure equipment creates huge amount of alarms saturating operators alarm management systems. In parallel the numbers of types of alarms have increased to overwhelming proportions.
Major mobility network incident management centre can count alarms in n*100 000 per day. Handling of n*1000 different types of alarms. Findings from independent researchers in telecom are frightening.
- >80% of all alarms results in a trouble ticket less than once every 1000 alarms
- >90% of all tickets are from <30 most common alarm types
- The alarm severity levels have no correlation to the real priority as judged by the network administrators
The majority of the alarms should never have been presented for the network administrators. The fundamental problem is that the network administrators are flooded with alarms and alarms with often poor quality.
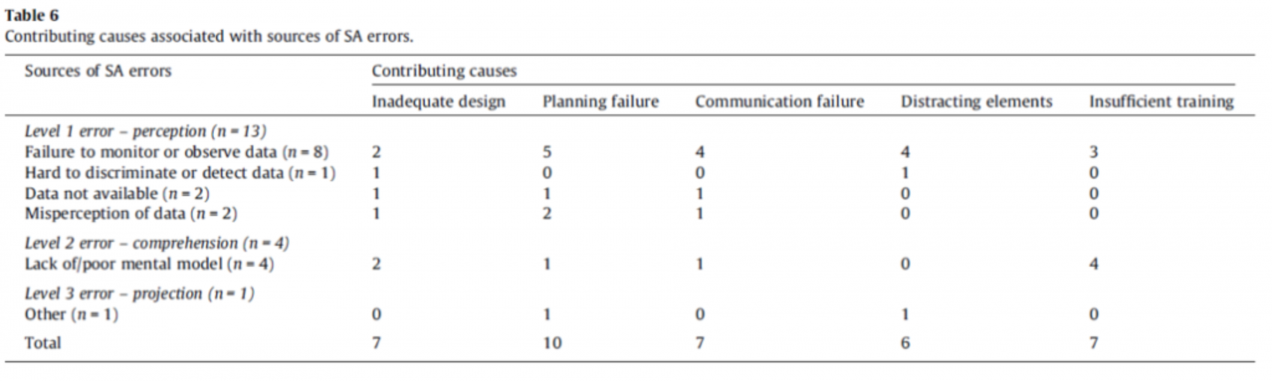
2. Maritime, from Situation awareness in bridge operations – A study of collisions between attendant vessels and offshore facilities in the North Sea:
In eight cases, the source of the SA error was the bridge crew’s failure to monitor or observe critical available information.
In five of these cases, the bridge crew failed to detect settings in the vessel’s technical system. Notably, two cases followed an almost identical course of events in that they were both caused by the bridge crew believing that the vessel was on manual steering when it was actually on autopilot.
In general it is fair to conclude that any industry that has the human in the loop and deals with a vast amount of streaming data that needs to be ‘processed’ by the human in the loop inherently has Situational Awareness issues.
History Repeating?
The proliferation of digital control systems which took a flight in the mid-nineties caused an incredible increase in the number of control loops, under the control of an operator, and an inflation in number of configured alarms. The drive behind this often: if you can measure it, have spent the money to wire and measure it, then display it and configure alarms on the signal (even when it was an input for a secondary control function).
The consequence of this caused issues. Irrelevant information presented to operational personnel that causes resulting risks, for those in the first line of control, such as:
- Stress of being overwhelmed by too much data information
- Inability to prioritize incoming streams of important data and information
- Inability to determine what data/information is needed and what can be ignored
- Not knowing anymore what source/sources can be trusted
The immense growth of sensors, in the IIoT arena, and vendors that have not dealt with similar issues can cause a repeat of this if we do design the systems correctly and fight information overload from the start.
Fight Information Overload
The first, most obvious, step is to lower the amount of information presented to the human in the loop. Take this example from ScanRaff Sweden:
The consequences of a trip of this compressor is that the heater will shut down, and so will the feed-pump. This is done by the safety system. So alarms that are meaningful to the operator in this situation are confirmation of heater shutdown and feed-pump shutdown, and the reason for the compressor trip.
- 392 alarms generated for the entire event
- 1 alarm every 2 seconds the first minute
- 254 alarms the first hour
- Operator acknowledged alarms 204 times
- 1 alarm was triggered 118 times
- 9 alarms were triggered more than 10 times
- Operator took 79 actions
- Theoretical minimum of actions were 39
- Event lasted 1.5 hours
It is obvious that the alarm system considered this to be 392 separate events while to the operator this was one event, a compressor trip.
You can conclude from this example that much of the information presented is irrelevant (state/situation dependent) and as such could be hidden from the operator’s view.
Consequential alarm/event analysis can help you here to greatly reduce what is presented (and requires action). Next to this, a bad-actor analysis around the time of the trip will certainly highlight the alarms that just cause nuisance.
These first measures, you could argue, are fire-fighting measures. But they work bringing the initial overload situation down to a more manageable one. Following this you must think through what information you want presented, how and why to further (more fundamentally) resolve the issue.
We have applied lessons learned in manufacturing industry to for example the Telecom industry and can conclude that even though different goods are produced and service are provided the issues are very similar.
If you want to find out how UReason can help you in improving our situation awareness using Predictive Maintenance and other technologies, feel free to download our ebook.