Back in the bad old days, companies used to run their plants until something failed. Then they’d stop (because they had to) and fix the broken parts and then run-to-fail again. In manufacturing plants, they tried to time themselves to get to the end of the model year or a similar point, and then they would shut down and re-tool and repair. In the process industries, especially in the refining and chemical plants, they would do a “turnaround” where they’d come through and replace everything that they thought might not make it until the next “turnaround.” That became known as preventive maintenance because they replaced assets and sensors even if they weren’t broken.
Both run-to-failure and preventive maintenance are very costly, both in downtime and lost production. Look at what happens when, for example, a polymer reactor is shut down full of product because something failed—a valve, a compressor, a pressure sensor, a flow meter—and the reactor shut down with product in it, and started to cool down. Now you get to either replace the reactor vessel entirely, or go into it with chisels and chip out the hardened polymer so you can start the system up once again. It might take weeks or months to get the process train going again. And all that time, maintenance costs money and there’s no product coming out the back door of the plant. It has been known to happen that a failure of a major asset in a plant caused a concatenating failure big enough to make the plant not worth re-starting.
So, if run-to-fail maintenance and most preventive maintenance is too expensive for modern manufacturing and process plants, what’s next?
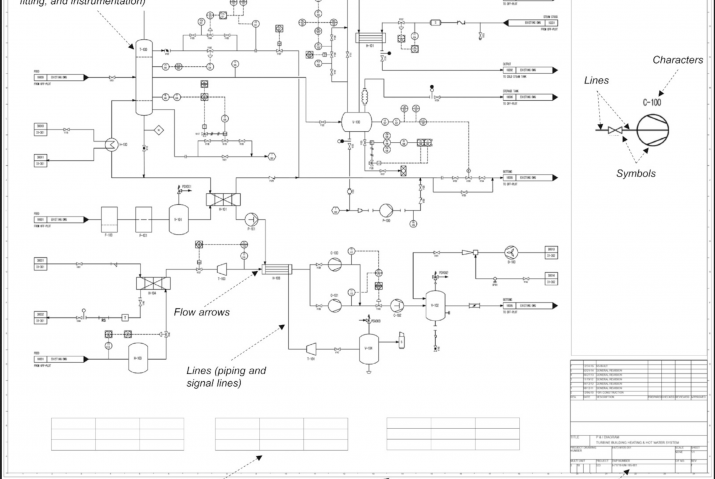
The problem has always been that plants, whether discrete manufacturing or batch or continuous process plants, have been incredibly complicated and they are continuing to get more complex. Plants have thousands of sensors, transmitters, analyzers, motors, motor controls, pumps, compressors, conveyors, assembly lines, you name it. Not to mention the control systems, communications, plant level networks, and more. And, if your plant is over a decade old, you don’t have accurate as-built drawings, or equipment lists. You may never have had accurate as-builts or equipment inventories. So how do you decide what assets need maintenance when you don’t know what assets you have?
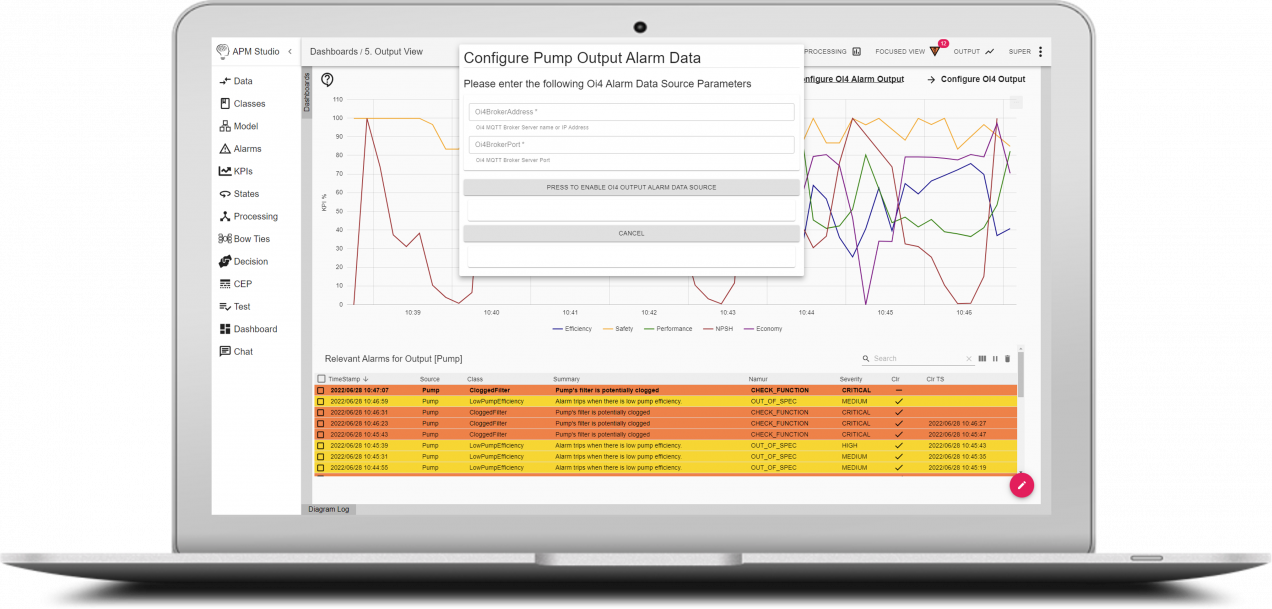
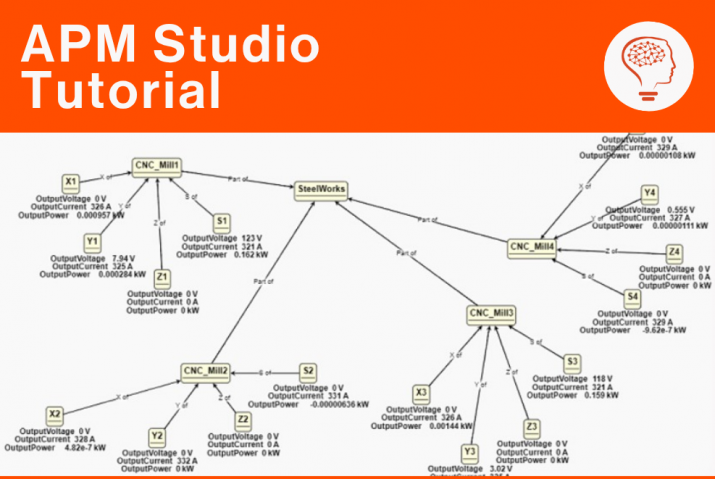
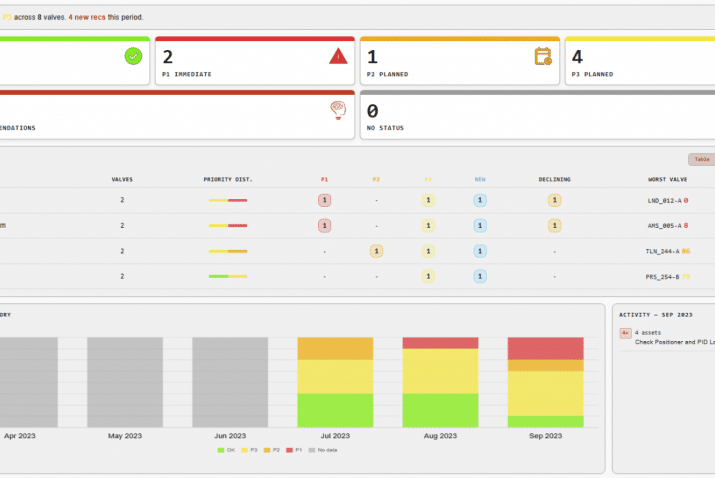
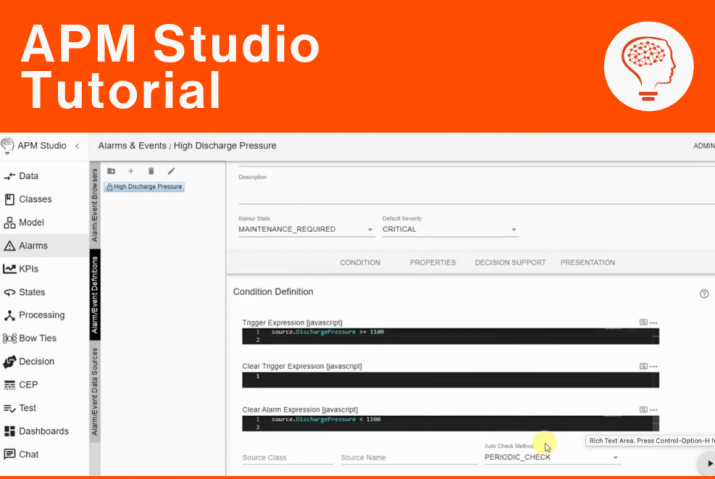
Now there are a complete set of tools to help you perform prescriptive maintenance and reduce the amount of unplanned downtime you face. Digitalization and the Industrial Internet of Things have made it possible to see exactly what assets you have, even if you have an elderly plant. You can use 3-D photography to identify your assets. You can use cloud-based databases to store your data. You can use asset management tools like UReason’s APM Studio to create digital asset cards and you can use the Artificial Intelligence embedded in UReason’s software to learn the causes and consequences of unplanned asset failure with easy-to-understand displays and cause/consequence models.
Even more important, UReason software is designed so that anybody in engineering or maintenance can work with it. Because it is capable of constructing analytical models with live data, visualizing cause/consequence models using bowtie models makes it simple to see and predict what failure events can occur and so something about them before they occur. As your assets become smarter, thanks to the IIoT, they will help you predict maintenance issues faster than ever. APM Studio can be embedded inside a device, or integrated with higher level software like PLCs, DCS/Scada systems, all the way to CMMS and ERP systems. The insights you will get from using APM Studio will allow you to continue to reduce unplanned downtime.
How low can you go? As your devices get smarter, like the Krohne/Samson FOCUS ON series and others, you will be able to iteratively reduce downtime. Is it possible using prescriptive maintenance to reduce unplanned downtime to zero? Won’t you have fun seeing if you can!
Click here for an eBook that explains how this works, and click here to have a UReason APM expert contact you for a demonstration.