What is prompt engineering?
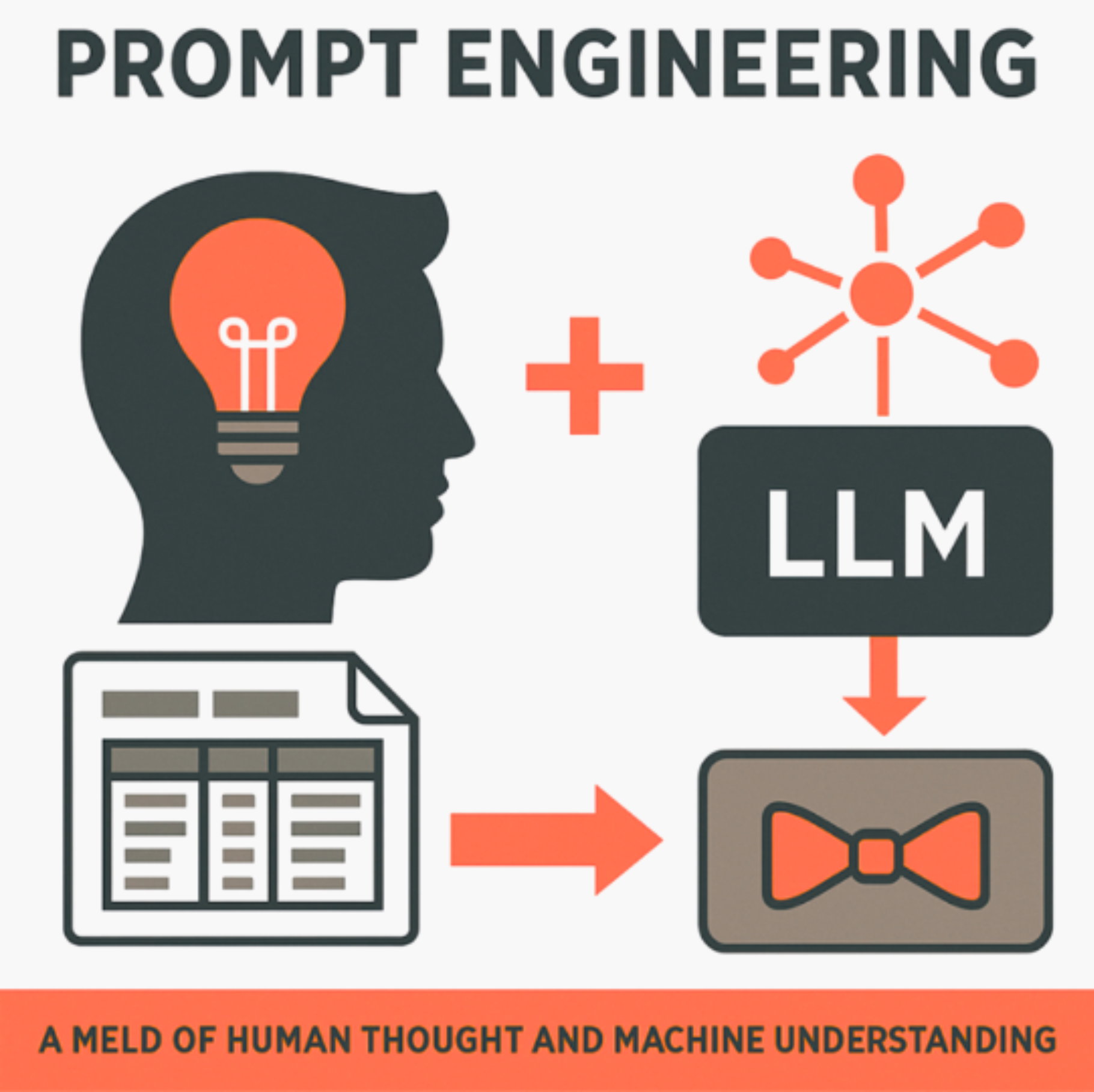
Prompt engineering refers to carefully designing the instructions given to a large language model so that its output aligns with the user’s goals. At its simplest, prompt engineering is the art of talking to LLMs. It might involve rephrasing a question to make it clearer or extending it to have more structure where examples are included to guide the model’s reasoning, or chain-of-thought prompting, which encourages the model to follow a set of steps before answering.
As LLMs become more capable, they remain sensitive to how a task is framed. A vague or ambiguous prompt can still lead to inconsistent or misleading outputs. In contrast, a well-crafted prompt can reduce hallucinations, sharpen focus on relevant details, and ensure the output is usable. Prompt engineering is a skill: it shapes the dialogue between human intent and machine response.
In practice, this means LLM users who understand prompt engineering can extract more reliable, task-specific outputs from a language model. It remains a valuable discipline, particularly in safety-critical contexts, where precision and consistency matter.
Why does it matter in structured risk analysis?
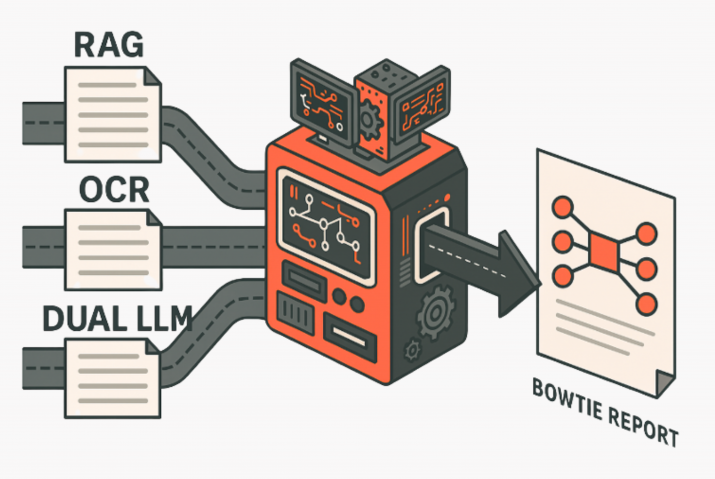
In domains like reliability engineering and safety analysis, the stakes of language model outputs are much higher, since consequences can lead to plant shutdowns, loss of revenue or greater safety concerns for workers. A Bowtie diagram must capture a failure event’s causes, mechanisms, consequences and the appropriate barriers. If the prompt does not clearly direct the model to extract structured elements from an FMEA, the results can be incomplete, and misleading, which is unacceptable in reliability engineering.
Prompt engineering is critical in this context as it bridges the gap between technical documents (with FMEA tables or dense text) and the structured visual representations needed for quicker analysis. Prompt engineering helps the model focus on relevant details, adhere to defined output formats, and minimise hallucinations by shaping how the task is described. This ensures that the diagrams generated are not just plausible but also actionable.
In testing, three prompting strategies were applied to the task of extracting Bowtie components:
- Zero-shot prompting: The model is asked to produce outputs without any prior examples, relying entirely on the context and the provided instructions.
- Few-shot prompting: A handful of worked examples are embedded in the prompt, demonstrating how unstructured input should be converted into structured output.
- Chain-of-thought prompting (CoT): The model is encouraged to reason step by step, breaking down the task into intermediate logical stages before delivering the final structured output.
How the Experiment Was Designed

The experiment set out to measure how different prompting strategies, combined with varying levels of instruction, influenced the ability of LLMs to generate Bowtie diagrams from structured data. Three prompt types were explored: zero-shot, few-shot, and chain-of-thought. Each type was tested at three strictness levels. At the lowest level, prompts were minimal or generic; medium levels added moderate scaffolding, such as mapping some FMEA fields to Bowtie roles; and high strictness enforced explicit stepwise logic, role mapping, and output constraints. Three models were tested: Mistral Instruct, Llama 3 Instruct and Qwen 2.5 Instruct, all between 7-8 billion-sized parameters.
To evaluate performance, we used three complementary metrics. Node-level metrics checked whether the model identified the correct causes, mechanisms, barriers, and consequences. Edge-level metrics measured whether those nodes were connected correctly within the causal structure. Finally, Graph Edit Distance (GED) calculated how many changes were needed to transform the model’s output into the expert Bowtie. These metrics revealed whether the right components were extracted and how well the underlying relationships were captured.
Data and Components used
The tests were run on Failure Modes and Effects Analysis (FMEA) tables drawn from the NWSC reliability handbook. Each table included failure modes, causes, and consequences, which served as ground truth for Bowtie construction. We looked at three components using their corresponding FMEA tables: individual sensor, shafts and the valve assembly.
Results
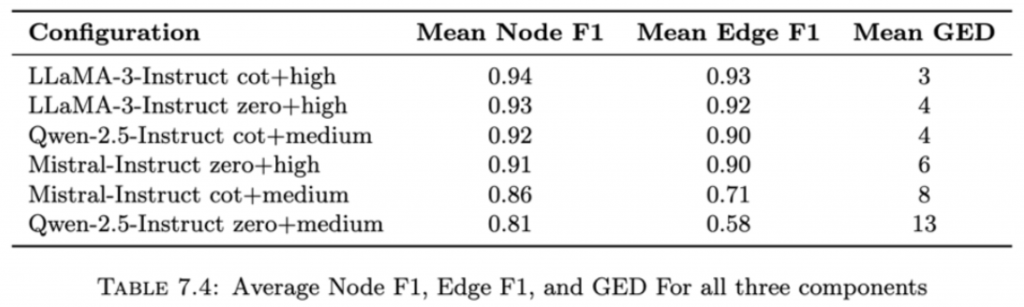
Performance hinged far more on how the task was framed than on model size or decoding parameters. The best-performing setups consistently used zero-shot or chain-of-thought (CoT) prompting with higher strictness levels. For instance, LLaMA-3-Instruct with CoT+high or zero-shot+high achieved mean node F1 scores of 0.94 and 0.93, edge F1 above 0.92, and minimal structural errors reflected in low Graph Edit Distance (GED).
Mistral-Instruct showed a similar pattern, performing strongly under zero-shot+high (mean edge F1 ≈ 0.90) but struggling when CoT prompts were paired with only medium strictness, where edge F1 dropped to 0.71. Qwen-2.5-Instruct displayed the widest variability: it reached solid scores under CoT+medium (node F1 = 0.92, edge F1 = 0.90) yet collapsed under zero-shot+medium (edge F1 = 0.58, GED = 13). These differences highlight how fragile performance can be when prompts lack sufficient scaffolding.
A notable outcome was that few-shot prompting was deliberately not chosen for this experiment. Early experiments showed it often introduced hallucinations into the output and hence was omitted. Instead of reinforcing structure, few-shot examples sometimes confused the models: they either ignored the examples altogether or misapplied them, producing malformed JSON or skipping entire Bowtie components. This instability made few-shot prompting less practical for structured risk analysis, where consistency and role accuracy are critical.
The broader lesson is that prompt engineering is not optional; it defines whether outputs are usable. Strong prompts with explicit schema guidance help models place causes, mechanisms, barriers, and consequences into the correct roles. Weak or underspecified prompts increase the risk of omissions and hallucinations, especially as diagrams grow in complexity. Reliable Bowtie extraction at scale depends less on tinkering with hyperparameters like temperature and more on careful design of prompts that enforce structure.
Good vs. Bad LLM output
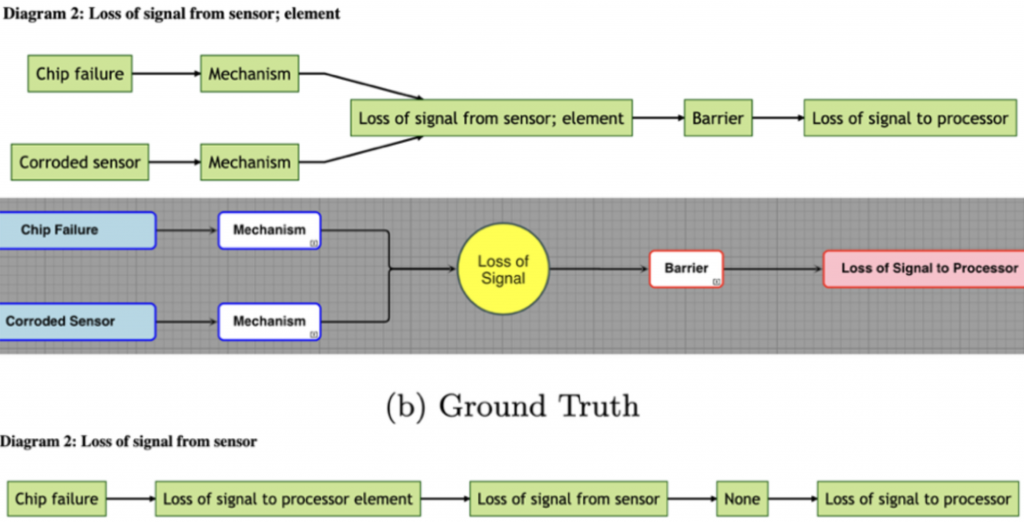
The contrast between outputs highlights why prompt design matters so much in Bowtie generation. The top diagram comes from LLaMA-3 with zero-shot, high-strictness prompting, while the bottom is generated by Qwen with zero-shot, low-strictness prompting.
With stronger prompt scaffolding, LLaMA-3 correctly identifies the failure modes (chip failure, corroded sensor), maps them to mechanisms, and links them to the central event of signal loss. From there, it follows the Bowtie logic by placing a barrier and showing the downstream consequence of losing the signal to the processor. This structure closely mirrors the expert ground truth.
In contrast, Qwen fails to build the proper causal chain under weak prompting. Critical distinctions are lost: “loss of signal” appears twice in inconsistent roles, barriers and mechanisms are absent, and the relationships collapse into a sequence that misses the core logic of the Bowtie.
Without clear and strict instructions, models often produce inconsistent Bowties that undermine their value in failure analysis. By contrast, high-strictness zero-shot or chain-of-thought prompts help enforce correct role assignments, yielding Bowtie diagrams that are both reliable and actionable for engineering applications.
Ready to explore your digitalization challenges together?
Book a call with Artur Loorpuu, Senior Solutions Engineer in Digitalization. Artur specialises in turning industrial challenges into practical digital solutions through expertise in predictive maintenance, digital twins, data science, and strategic product management.
Let’s explore how we can support your goals!