For some time now we have been researching how in addition to recommendations, provided by the Control Valve App, we can support our users with Generative AI, specifically Large Language Models.
Large Language Models (LLMs) are a class of artificial intelligence models that are designed to understand and generate human language. These models are characterized by their immense size, as they are built upon deep neural networks with a vast number of parameters, often in the range of hundreds of millions to tens of billions. Large Language Models are pre-trained on massive amounts of text data, which allows them to learn the nuances of language and a wide range of linguistic tasks. They are part of the broader field of Natural Language Processing (NLP).
Large Language Models (LLMs) are a new type of deep learning algorithm, a subset of machine learning, within the domain of Natural Language Processing (NLP). Commonly known LLMs include OpenAI’s ChatGPT, Meta’s LLaMa, Google’s Bert, and Mistral’s Mixtral models. These LLMs make use of deep learning to generate and interact with human language in a way that is revolutionary compared to prior methods.
Large Language Models (LLMs), which are primarily designed for natural language processing tasks, may not be the most suitable choice for working directly with time-series data which we have in abundance in the Control Valve App. The time-series we receive and generate are sequences of observations such as setpoint and position data but also issues found by the CVA such as stiction, overshoot, undershoot et cetera, collected at successive time points. LLMs are not specifically designed to handle the unique characteristics of such data. However, LLMs can still be used in combination with other techniques to work with time-series data effectively.
In our research we started to work with the LLM from Meta: LLaMa 2. This because it has a kind of an open-source license. As long as we do not have more than 700 million monthly active users. For our users of the Control Valve App, this means that we can productise it and charge the infrastructure costs associated with running LLaMa 2 for their valves. But let’s not get ahead of the game and return to some of the theory and our findings first!
Fundamentals of LLMs
Neurons and Neural Networks: At the core of LLMs are artificial neurons, computational units which are inspired by biological neurons. Each neuron receives an input, processes the input through an activation function, and returns an output. Deep learning algorithms, including LLMs, all make use of large quantities of these neurons organized in layers, organized into various architectures, such as the transformer architecture, hence ChatGPT’s name as Generative Pre-trained Transformer.
Neuron Weights and Parameters: The “strength” of a connection between neurons is known as a weight. These weights essentially are the parameters that the model learns during training. In LLMs, the term parameter count is frequently used, and these models can easily reach over 175 billion parameters (GPT3.5 uses 175 billion, GPT4 has over 1 trillion). Each weight/parameter is adjusted during the training phase of the deep learning model, in such a way as to minimize the difference between the model’s generated output and the expected output.
The size of LLMs has increased rapidly in the past few years and is expected to grow even more:
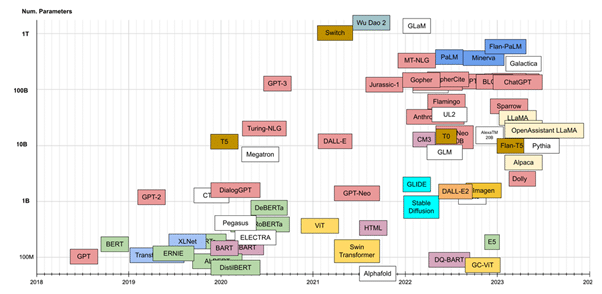
Transformer models: an introduction and catalog, Xavier Amatriain et al.
Parameters and Model Capacity: The number of weights/parameters in an LLM is a loose indicator of its capacity to learn “complex concepts”. Weights principally hold some aggregated knowledge derived from all the training data the model is shown, and these weights are later used to make predictions or generate text on new unseen data. Theoretically, higher parameter counts are expected to lead to increased understanding, given more connections and variations can be modelled (think of a 2D grid vs a 3D grid, all 2D lines can be drawn in the 3D grid, along with more). However, increasing the complexity/depth/size of the model demands leads to significant increase in representative training data, something which is difficult to achieve (and takes a longer time to train).
Architecture Overview
Transformer Architecture: Currently, most LLMs have shifted to using the Transformer architecture, introduced in the paper “Attention is All you Need” by Vaswani et al:
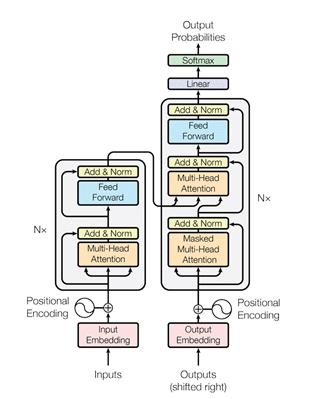
The architecture replaces previous recurrent mechanisms for deep learning NLP models with an attention mechanism, allowing the model to weigh the importance of different words individually across the input text. Moreover, the biggest advantage of the attention block is that it allows for parallel processing of tokens, compared to the previous recurrent blocks.
Context Size and Memory: The context size of an LLM determines how many tokens, words or pieces of a word or punctuation, the model can process in one go. This is an architectural choice by the LLM designers. Larger context windows allow for more information to be provided in one go but require higher computation resources (RAM or VRAM). Larger context windows likely help the model in gaining a more thorough understanding of complex comprehensive texts but may not benefit the model when performing simple language tasks that require little background information (analysing a book may require a large context but answering “How are you?” may not).
Training vs Inference
There are two stages in any deep learning process, training and inference.
Training: Training is the process of adjusting the model weights/parameters by providing examples with an expected output (supervised learning). This process requires a lot of data, and there is no known fixed number. Larger and more complex models require magnitudes more data than simpler ones.
Inference: Inference is the stage of LLM usage which most individuals are familiar with. Once the model has been trained (i.e. the model weights are adjusted based on training data), the model can make predictions on new text. During this process, the model stops adjusting weights and simply uses the state post-training. This stage requires far less computational resources than the training stage but still requires quite some resources.
Resource Requirement: For smaller LLMs, such as LLaMa 7b (7 billion parameters), the model can be used for inference on a high-end CPU with appropriate RAM (14GB RAM). Larger models, such as LLaMa 70b (70 billion parameters) can only be run with acceptable response times on a Graphics Processing Unit (GPU) or Tensor Processing Unit (TPU) and require magnitudes more memory (140 GB RAM/VRAM). For memory calculations, each weight requires 2 bytes of data. Hence, in a 70 billion parameter model, 70 billion * 2 bytes = 140 billion bytes = 140 gigabytes.
Quantization
As previously described, the size of the models can get very large (GPT4 with 1 trillion parameters = 2 terabytes of RAM/VRAM). To address this, a method was used called “quantization”. The principal idea behind quantization is to use fewer bits per weight/parameter. For, let’s say LLaMa 70b, with 70 billion parameters, instead of using 2 bytes per weight, we instead use only 1 (so 8 bits), or only 4 bits (half a byte). In doing so, the computational requirements of the model are reduced, while the size/complexity of the model remains.
Typically, the quantization process happens after the training phase, but there are methods to combine quantization into the training phase. Post-training quantization involves analysing the distribution of weights and activations and mapping these to a lower precision format. Quantization-aware training simulates the effect of quantization during the training process, allowing the model to adjust its parameters on the fly.
There are pros and cons to quantization.
Pros:
- Reduced computational resources
- Increased inference speed
- Lower power consumption
- Model complexity (number of neurons) remains unchanged
Cons:
- Loss of model accuracy
- More complex to implement
LLMs in NLP
In generative NLP, LLMs have set a new standard for creativity and versatility for text generation. These models can be used to generate poetry, dialogue, articles, blog posts, or even to complete text. The model’s training data includes an immense variety of writing styles and content, giving it range in its generative abilities.
For many people, LLMs have also been used for code summarization and generation, being able to suggest code snippets, complete entire programming tasks, or generate and refactor entire programs based on natural language descriptions.
LLMs beyond NLP
Surprisingly, the utility of LLMs extends beyond text generation, with the paper “Temporal Data Meets LLM – Explainable Financial Time Series Forecasting” by Xinli Yu et al. Showcasing the capability of LLMs in stock market time-series prediction. The sequential nature of time-series data, like languages, allows LLMs to predict upcoming data points in fields ranging from finance to engineering. Furthermore, both time-series and language data can be provided. In the aforementioned paper for instance, the numerical data is provided along with news article snippets, allowing the model to reason between both elements of the context.
Up Next: Our use case in applying Large Language Models
Get Full Access of UReason LLM Report Q1/2024
Fill in the form to get full access of our report, including exclusive sections and unreleased chapters