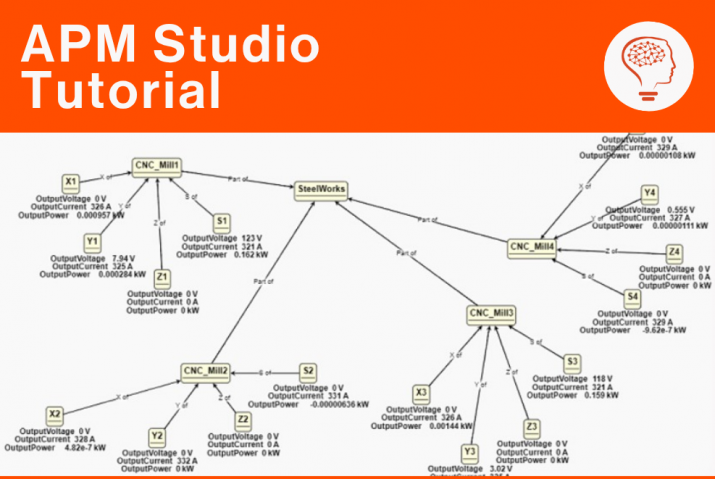
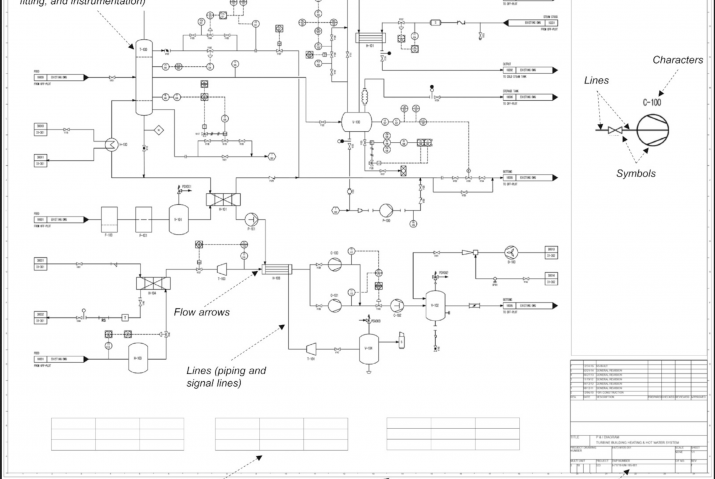
At UReason, we investigated the application of LLMs to the Control Valve App (CVA). The rationale for spending time on LLMs is driven by the creeping scarcity of knowledge and expertise in industry. As experienced people, that often have spent their entire professional career with one company leave. This is quite normal, however we see ‘replacement’ by individuals that often don’t spend more than 4-to-6 years in the same role and have less knowledge and skills. This change of workforce requires smarter systems that can utilize asset’s history like people used to. Hence our investigations focussed on applications ranging from human interaction with Chatbots, in the form of smart database querying, to data analytics/science cases that analyse raw and processed data from control valves.
Models Investigated
We investigated a variety of different models and sizes of models against which we benchmarked performance (on known comparative benchmarks), required computation resources, and compared licensing options for commercial use.
Model Size and Capacity
The models we evaluated are:
- GPT-3.5: A 175 billion parameter model by OpenAI. 16000 tokens context size.
- GPT-4: An over 1 trillion parameter model by OpenAI. 128000 tokens context size.
- LLaMa2-7b: Meta’s smallest 7 billion parameter model. 32000 tokens context size.
- LLaMa2-13b: Meta’s mid-sized 13 billion parameter model. 32000 tokens context size.
- LLaMa2-70b: Meta’s larger 70 billion parameter model. 32000 tokens context size.
- Mixtral-7b: Mistral’s smaller 7 billion parameter model. 8000 tokens context size.
- Mixtral-8x7b: Mistral’s mixture of experts with 47 billion parameters. 32000 tokens context size.
Each model has its own architectural design, which influences the way in which context is treated. For example, Mixtral uses a sliding window over the context, instead of using the raw context in its entirety. (And remember tokens are the words, or pieces of a word or punctuation, the model can process in one go.)
Benchmark Performance
Evaluation of the quality of language models is mostly done by comparison to human created sample benchmarks created from typical language-oriented tasks. Other, less established, quality tests examine the intrinsic character of a language model or compare two such models.
Since language models are typically intended to be dynamic and to learn from data theyit sees, some proposed models investigate the rate of learning, e.g. through inspection of learning curves.
GPT
- GPT-3.5 and GPT-4 have set benchmarks in NLP from the moment they were introduced to the world late November 2022. They show remarkable performance in understanding context, generating text across genres and styles. GPT-4 is largely better than GPT-3.5, with more refined answers and greater accuracy.
LLaMA
- The performance of Meta’s LLaMa models is surprisingly good, given the significantly smaller model sizes compared to ChatGPT models. The performance scales from the smallest to the largest model, with the larger 70b model rivalling GPT-4 on some select benchmarks.
Mistral
- The Mistral models have a bigger focus on speed. The 7b model is very fast. The Mixture of Experts 8x7b model, which makes use of 8 separate 7b models, shows impressive benchmarking results, frequently outperforming the LLaMa 70b model.
A core element overlooked in the current explanation of the models and their performance is the ability to further fine-tune these models. LLaMa and Mistral have shared their model weights for the mentioned models publicly online, for free, allowing users to further train these models on custom datasets, of various kinds. Though the Mixtral 8x7b and LLaMa 70b are comparable, the fine-tuned variants of Mixtral 8x7b consistently outrank the fine-tuned LLaMa models on the OpenLLM leaderboard of HuggingFace (a very popular LLM/DL hub).
Computation Resource Requirement
Another important metric to consider when starting to employ LLMs is their hunger for compute resources (CPU/GPUs and RAM/VRAM).
GPT
- Both GPT models require immense computational resources and cannot be fully used on regular consumer hardware. A typical GPT-4 model can run on a Nvidia DGX A100 node, which has 8 A100 GPUs of 80gb VRAM.
LLaMa
- The different sizes for LLaMa offer flexibility on the computational requirements. The 7b model can easily be deployed on regular consumer-grade CPUs. The 70b model, requires more robust infrastructure, requiring multiple GPUs or an Nvidia node.
Mistral
The Mistral 7b model is designed for usage on regular hardware. The 8x7b, though larger in size, requires less resources than both GPT and LLaMa models.
With quantization, these requirements also change. In the case of LLaMa or Mixtral 8x7b, quantized model weights exist on HuggingFace, allowing for them to be used on consumer-grade GPU or TPUs. An interesting, very recent article: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, by Shuming Ma et al., shows interesting progress in lowering the hardware requirements so LLMs could run on edge and mobile devices.
Licensing for Commercial Use
Perhaps most import is the licensing models that the LLM employs. Understanding the complexities of various licenses can be off-putting.
GPT
Requires a subscription to OpenAI’s API, with costs scale based on usage.
LLaMa
More open than GPT. Free usage until the company has a certain number of users and you can’t use LLaMa 2 to generate training data for either building or fine tuning any other model, which is potentially more of a problem as lots of people might want to do this.
Mistral
The most open as Mistral is released under the Apache 2.0 license which is a favourable license. See: https://www.apache.org/licenses/LICENSE-2.0.
Up Next: Our work in applying Large Language Models
Get Full Access of UReason LLM Report Q1/2024
Fill in the form to get full access of our report, including exclusive sections and unreleased chapters